










воскресенье, 28 января 2018 г.
Создание электронных книг из сканов. DjVu или Pdf из бумажной книги легко и быстро
Предисловие автора
Итак: перед вами взятая у приятеля, из библиотеки, или просто хорошая, интересная книга, которую хотелось бы иметь на компьютере. И не просто иметь, а иметь в таком виде, который позволил бы выполнять поиск по тексту, удобно читать книгу на экране монитора или на устройствах еВоок, а если это не научно-техническая или справочная литература – еще и читать на любимом сотовом телефоне, iPhon'e или PDA. В этом пошаговом руководстве, основанном на собственном опыте, я постараюсь рассказать о том, как «выжать» максимум результатов из проделанной простой, но иногда весьма утомительной работы по сканированию книги.
Пусть вас не испугает длина этого руководства и кажущаяся сложность сканирования и обработки книги. Процесс действительно довольно сложен и многоступенчат, но поверьте мне, описать все эти операции было гораздо труднее, чем выполнить их шаг за шагом.
Итак, ПОЕХАЛИ!
Шаг 1. Сканирование
1.1 Подготовка к процессу
Сканирование, с которого начинается, зачастую, долгий путь «в Сеть» любой изданной когда-либо книги (рынок легальных электронных книг, размещаемых издателями непосредственно после электронной верстки, у нас совершенно неразвит) – это самая монотонная часть всей предстоящей работы, поэтому к ней стоит тщательно подготовиться заранее – протереть стекло сканера, проверить наличие свободного места на диске – несжатый скан одной средней по размеру книги может занимать до 1 Гбайт. Потом начинается собственно сканирование.
Я намеренно не привожу здесь сравнительных характеристик разных моделей сканеров, поскольку каждый из нас в подавляющем большинстве случаев располагает только одним сканером, характеристики которого более или менее хорошо известны.
Phistek OpticBook: преимущества и недостатки

Из всех сканеров, имеющихся на рынке, для сканирования книг в больших количествах нет ничего лучше серии Plustek OpticBook. Эти планшетные сканеры отличаются высоким корпусом и прозрачным основанием, выполненным "в край" – так, чтобы на него можно было уложить книгу, не ломая и не деформируя корешок. Такой сканер – идеален для перевода в электронный вид десятков томов, например из библиотеки университетской кафедры. Однако, для домашнего повседневного применения он практически непригоден. Причина этого – в сугубой спецbализированности устройства под книгосканирование и OCR. В конструкции PlusTek OpticBook в жертву быстродействию и разрешению принесено все, что только можно, включая четкость, избирательность и цветопередачу.
Сканирование всех своих книг я проводил и провожу на достаточно старом (2003 года выпуска) полупрофессиональном планшетном сканере для документсистем Hewlett-Packard ScanJet 6390с. Эта машина отличается высоким быстродействием (15-25 сек на страницу формата А4 в режиме градаций серого). Кроме того, в ее комплект поставки входит удобное программное обеспечение HP Precision Scan Pro. Именно на этой программе сделаны все скрины с примерами сканирования.
1.2 Сканирование
Заранее хочу предостеречь от использования в качестве основного инструмента сканирования программы FineReader. Оставим эту программу до стадии OCR. Пока она может лишь максимально усложнить нам задачу пакетной обработки, применив (причем, без нашего ведома) – свои не слишком хорошие алгоритмы чистки и сжатия сканов. А главное – она практически лишит нас шансов применить важнейший прием – оверсемплинг до разрешения 600 dpi.
Собственно сканирование состоит из трех этапов: сканирования обложки, основной части книги, цветных вклеек и иллюстрации. Последовательно описывать эти этапы нет смысла – они переплетаются друг с другом в зависимости от верстки книги. Стоит привести лишь параметры сканирования, оптимальные для разных типов книжных страниц.
Здесь приведу еще одно важнейшее предупреждение(!):
На некоторых очень старых моделях сканеров есть возможность вручную включать внутренний оверсемплинг, тo есть фактически сканировать с меньшим разрешением, чем имеет выходной файл. Обозначается такая установка разрешения обычно словом Software или Resampled. Эту установку использовать нельзя! Ее включение приведет в полную негодность полученные файлы, и их дальнейшая обработка окончательно потеряет смысл. Также нельзя использовать установку сканирования в режиме Linearеt или Black amp;White(одноцветный)
Общие рекомендации такие: для текстовых страниц используйте:
• Режим Grayscale (оттенки серого), для цветных иллюстраций и обложек – True Color (полноцветный).
• Разрешение сканирования – 300 dpi (только оптическое, повторимся еще раз!).
• Остальные установки можно оставить по умолчанию.
Таблица 1. Оптимальные параметры сканирования
Эти параметры не являются догмой. Они определены опытным путем на нескольких моделях неспециализированных сканеров, и служат ориентировочным целям. Собственный набор оптимальных параметров книгосканирования всегда стоит определить экспериментально, отсканировав любимую книгу со всеми иллюстрациями и обложкой. Приводя эти параметры, я стремился обобщить их для применения на максимальном количестве моделей сканеров.Тип страницы: Страница с черно-белым текстом без иллюстрацийРежим: GrayscaleРазрешение: 300 dpiРезкость: Low или MediumЯркость и контраст: Любые, специальные параметры не использоватьТип страницы: Страница с черно-белым текстом и черно-белыми штриховыми (одноцветными) иллюстрациямиРежим: GrayscaleРазрешение: 300 dpiРезкость: Medium. HighЯркость и контраст: Любые, можно применить пресет B amp;W PhotoТип страницы: Страница с черно-белым текстом и черно-белыми фотографическими иллюстрациямиРежим: GrayscaleРазрешение: 300 dpiРезкость: High можно применить пресет B amp;W PhotoЯркость и контраст: Определяются по предварительному сканированиюТип страницы: Страница с черно-белым текстом и цветными иллюстрациямиРежим: True ColorРазрешение: 300 dpiРезкость: Low, можно применить пресет PhotoЯркость и контраст: Определяются по предварительному сканированиюТип страницы: Цветная обложка или иллюстрация страничного форматаРежим: True ColorРазрешение: 300 dpiРезкость: Low, можно применить пресет PhotoЯркость и контраст: Определяются по предварительному сканированию
Формат выходного файла: Uncompressed (Несжатый) TIFF(!)
Почему не JPEG?Формат JPEG для сохранения сканов книжных страниц использовать можно, но не нужно.Во-первых: потому, что этот формат даже при включенном сжатии без потерь (Quality = 100) оставляет артефакты в виде «квадратиков».Во-вторых и самых главных: многократное пережатие при сохранении обработанного файла JPEG вновь в «свой» формат за 2-3 цикла обработки приводит изображение в негодность.Отдельно коснемся использования сжатого (Compressed) TIFF: при сохранении сжатого изображения в TIFF можно использовать алгоритмы сжатия: ZIP. LZW (без потерь). JPEG (с потерями). Без хлопот программы распознавания вроде FineReader понимают только JPEG.Со всеми остальными форматами проблемы могут возникать непредсказуемо (например, у меня FineReader 7.0 испытывает устойчивую «идиосинкразию» конкретно к формату сжатия LZW). Поэтому если нет особых проблем с наличием места на диске, лучше всегда использовать несжатый файл.
Итак, сканер включен, программа управления запущена.
Кладем книгу на предметное стекло сканера таким образом, чтобы охватить обложку (с нее лучше всего начинать сканирование). Включаем предварительное сканирование и настраиваем изображение инструментами программы управления сканером, добиваясь максимального соответствия оригиналу. Когда параметры выставлены, сохраняем переднюю и заднюю страницы обложки в файлы с информативными именами (типа cover_front, cover_back), чтобы потом исключить их из пакетной обработки основной части книги.
Отсканировав обложку, вновь кладем книгу на стекло, но уже с открытой первой страницей и форзацем (если сканер имеет форматный фактор на стекле А4 или А4+? книгу с форматом страницы более А5 придется сканировать по одной странице, при этом придется отдельно сохранить форзацы). Предварительное сканирование запускаем еще раз. Параметры теперь нужно выставить таким образом, чтобы добиться хорошей контрастности текста и черно-белых иллюстраций.
Установка_области сканирования: область сканирования для книг (особенно при сканировании разворотами) – выставляется с запасом относительно формата книги, чтобы не особенно заботиться в дальнейшем о выравнивании книги на стекле. Это очень ускоряет работу: если не «швырять» книгу на сканер как попало – текст и хотя бы часть полей обязательно попадут в установленную область, а выравнивание изображения можно будет сделать при обработке. Задаем папку для сохранения выходных данных сканера. В зависимости от того, сканируется разворот книги, или одна страница, выбираем имя для первого файла.

Из личного опыта:Поработав с несколькими десятками книг, я пришел к выводу, что нумерацию файлов со сканами лучше всего начинать с нуля (например, Scan_000.TIF). Дело в том. что нумерация страниц в книгах обычно идет по схеме: Форзац =› Страница 1 (как правило, без номера) =› Страница 2 (данные типографии) =› Прочие страницы. Если сканировать книгу разворотами, то при нумерации с нуля номер каждого файла будет в точности равен номеру четной страницы, разделенному на 2, то есть:1. Разворот 1 (Форзац и страница номер 1) – файл с именем Scan_000. TIF;2. Разворот 2 (страницы 2 и 3) – файл с именем Scan_001. TIF;3. Разворот 3 (страницы 4 и 5) – файл с именем Scan 002. TIF;4. Итак далее…
Как правило, сканы именует сама программа сканирования, когда включен ее пакетный режим. Тогда заботиться об именах вообще не нужно. Однако у меня автоматическое именование работает (причем плохо) – только когда включен модуль автоматического листового сканирования ScanJet ADF. Поэтому я стараюсь давать своим файлам вручную простейшие цифровые имена, набивая их на нумпаде (заодно руки отдыхают от постоянного нажатия Ctrl+S).
Облегчить себе работу при сканировании – максимально насущная задача.
Если сканирование каждого отдельного разворота/листа включается клавишами (например теми же Ctrl+S) – нет проблем. Просто не меняя параметров области сканирования – жмете клавиши еще раз, набираете (или не набираете, если повезло с программой) имя очередного файла – и ждете окончания процесса. Если же без нажатия кнопки мыши не обойтись – ставите курсор на кнопку включения сканирования, и по окончании прохода очередной страницы – щелкаете пальцем по мышке, не сдвигая ее. При этом дожидаться, пока головка сканера вернется в исходное положение – никак не обязательно! Это только замедлит работу.
Описанным способом, в зависимости от быстродействия сканера, на один разворот уходит в среднем 18-25 секунд. То есть, при небольшом навыке можно выйти на «производительность ударного труда» порядка 160-200 разворотов (360-400 страниц) в час. Это значит, что в среднем за пару часов вы способны управиться даже с самыми толстыми томами! Немного усидчивости – и вуаля.
Маленькие хитрости

Крайне желательно, чтобы программа сканирования имела обновляемые пресеты установок области и параметров сканирования. Тогда, не закончив вечером работу над очередным томом, можно сохранить установки сканера, а потом – просто загрузить их.

В целом, чем проще будет для вас процесс сканирования – тем лучше. Главное для получения хорошего результата – следовать самым простым описанным правилам – получать выходной файл в формате несжатого TIFF, с разрешением 300dpi. Ну, и, само собой разумеется, в готовых файлах вы сами должны быть способны, не напрягаясь, прочитать текст.
Шаг 2. Пакетная обработка
После сканирования полученные файлы содержат страницы книги, иногда в довольно неприятном виде, вроде такого:

Смещенные и повернутые относительно друг друга страницы, низкий контраст, нечеткости печати во всей красе, затемненная область у корешка и полей – там, где книга неплотно прилегала к стеклу сканера. У такой страницы в неизмененном виде – мало шансов быть распознанной без ошибок, и тем более она не будет иметь никакого «товарного вида» после сжатия и упаковки в DjVu или PDF.
Устранить все дефекты и повысить качество распознавания текста – поможет пакетная обработка.
2.1 ScanKromsator V5.92
Салютуем альтруизму разработчиков-добровольцев!
Программа ScanKromsator 5.92 (автор – уважаемый камрад bolega) – объективно лучший на данный момент процессор пакетной обработки изображений, специально «заточенный» под книгосканирование. Скачать программу всегда можно здесь: http://www.djvu-soft.narod.m/soft/.
Программа ScanKromsator – мощный инструмент для подготовки книжных сканов. Она автоматически и наилучшим образом выполняет операции разбиения по страницам (Split), углового выравнивания (Deskew), обрезки переплетов и полей страниц. Однако, потратив несколько минут на расстановку опций и проверку страниц – можно получать всегда отличные легко распознаваемые сканы с минимальными (только не для компьютера) усилиями. Кроме того, программа может сохранять сделанные настройки в виде сведений о заданиях (Tasks). Это позволяет при работе с большими книгами не бояться задать неправильные установки после перерыва в работе.

Первый шаг при работе с Кромсатором – командой File=›Open Images… вызвать диалог открытия файлов с изображениями, и в нем выбрать ранее подготовленные сканы:
В диалоге открытия присутствуют списки, влияющие на открытие многостраничных TIFF-файлов (некоторые программы сканирования позволяют сохранить несколько сканов в один TIFF-файл), и сортировку файлов после сформирования списка. Опцию «Sort Smart» («Умная» сортировка) стоит держать включенной всегда, и не отказываться от сортировки, так как обычная техника выбора файлов в Windows с помощью мыши и клавиши Shift – меняет местами первый и последний выбранные файлы в списке. Для того чтобы выбрать файлы в любом диалоге Windows в правильном порядке, нужно:
• Выделить щелчком мыши последний файл из выбираемых:
• Нажать клавишу Shift:
• Щелкнуть на первом из выбираемых файлов.
Открытие сканов занимает, в зависимости от быстродействия компьютера – от нескольких секунд до примерно полуминуты. Когда изображения открыты, можно просмотреть их в вертикальном графическом списке файлов, а имена сканов – перечисляются в левом верхнем углу окна. В списке имен наличие зеленой галочки рядом с именем файла – означает, что файл готов к финальной обработке (прошел стадию автоматической установки границ). В случаях, когда в файл вносятся изменения, и он требует повторной обработки, его имя выделяется полужирным шрифтом.

2.2 Препроцессинг и расстановка границ
Каждая страница, обрабатываемая Кромсатором, перед основной обработкой проходит препроцессинг – первичную расстановку границ. При этом программа пытается определить положение корешка (при сканировании разворотов), обреза книги и полей страницы. Запускается препроцессинг командой Draft Kromsate меню Edit, или одноименной кнопкой (на кнопке – рисунок с ножницами) инструментальной панели.
При этом появляется диалог Draft Kromsate с тремя вкладками: Options, Preprocess и Advanced.
Собственно интерес будет представлять только вкладка Options, так как на ней выставляются все нужные на данный момент параметры. Список Kromsate позволяет выбрать, к каким файлам из списка будет применен препроцессинг. Опцию Pre-Rotate (вращение) следует использовать, когда развороты или страницы книги сканировались в «вертикальном» положении и не поворачивались программой сканирования. Флажок Save after rotate позволяет задать необходимость предварительного сохранения повернутого изображения (вот где важно отсутствие JPEG-сжатия!). Группа списков Use options from… задает возможность выбора одного из предварительно сохраненных наборов настроек.
Флажки в нижней части диалога задают параметры работы препроцессора, от них напрямую зависит качество результата, поэтому остановимся на них более подробно:
• Split Pages – задает разбиение разворотов на страницы. Включается в зависимости от формата книги и методики сканирования.
• Ignore blank half-page – разрешает программе самостоятельно исключать из обработки белые форзацы и просто страницы, не содержащие печати. Пригодится, если в книге есть отделение глав друг от друга белым листом.
• Safe top/bottom – установка этого флажка запрещает обрезку «полупустых» страниц и белых форзацев. Выключать не рекомендуется, особенно если книга предназначена для последующей распечатки – иначе не исключено наличие обрезанных не по формату «куцых» страниц.
• Бледный скан – вдвое снижает порог обнаружения контрастных границ текста и корешка. Применяется, если текст на скане очень бледен и трудно читаем (например, при сканировании различных руководств и многостраничных технических таблиц, напечатанных на полупрозрачной низкокачественной бумаге).

• Skip marked files – запрещает повторную обработку файлов, отмеченных зеленой галочкой, то есть уже прошедших препроцессинг.
• Select special processed – выбирает в списке файлы, отмеченные полужирным шрифтом (имеющие специальные настройки).
• Set only cutters – задает возможность не совершать никаких действий, кроме расстановки границ.
• Don't set cutter near border – запрещает установку границы слишком близко от края изображения. Применяется, если книга сканировалась со слишком большим запасом по полям.
Если границы выставляются неправильно (чаще всего такое происходит на бледных сканах), может помочь увеличение чувствительности поиска вертикальных границ текста – она регулируется ползунком Text vert. sensitivity на вкладке Advanced.

Когда все параметры выставлены, остается только нажать на кнопку ОК и подождать… от десяти минут до получаса, в зависимости от объема книги и быстродействия компьютера. После окончания препроцессинга окно программы изменится:

На поле редактирования изображения появляются линии обрезки, а на его краях соответствующие ползунки. Ползунки с L-образным рисунком обозначают границу обрезки поля страницы, ползунки с Т-образным рисунком определяют границы переплета.
Теперь настало время проверить расстановку границ на всех сканах.
Это утомительная, но совершенно необходимая часть работы.
В секции опций окна ScanKromsator выбираем вкладку Page, чтобы при необходимости отключать разбиение разворотов на страницы флажком Split. Потом начинаем листать страницы одну за одной.
Листание реализовано очень удобно: клавиша «W» листает страницы вперед, a «Q» – назад.
Таким образом, перебирая левой рукой страницы, можно очень быстро ставить мышью на место неверно установленные границы, перемещая их за ползунки (сами линии на поле редактирования не перетаскиваются).
При необходимости поставить наклонную границу, можно наклонить одну из линий, нажав клавишу Shift и потянув ползунок. Только не нужно злоупотреблять наклоном горизонтальных границ, это может привести к появлению страниц с текстом, растянутым в форме трапеции. Уже упомянутый флажок Split отключает разбиение разворота на страницы (в случае, если, например, в книге присутствует большое изображение на целый разворот, требующее дополнительного сведения в другой программе). Если ошибки в расстановке границ повторяются (такое бывает, например, когда при сканировании деформировался мягкий переплет), можно скопировать текущее положение одной из границ группой команд Copy current position to… контекстного меню, вызываемого щелчком правой кнопки мыши на ползунке. В этой группе особый интерес представляют команды all down и all selected, задающие копирование положения границы «до конца» списка или на все выбранные сканы. Контекстное меню также позволяет отключить наклон границы командой Reset Slope.

2.3 Опции обработки
Когда все границы выставлены как положено, приходит время расстановки опций. Встряхнитесь, ибо тут нужно предельное внимание – даже один неверный шаг наверняка будет стоить вам потраченных нервов и процессорного времени.
Итак, перед нами секция опций программы ScanKromsator.
Помните, что большинство выставляемых опций относятся только к выбранной странице! Чтобы распространить устанавливаемую опцию на все страницы, нужно при включении флажка или щелчке на кнопке держать нажатой клавишу Ctrl!
Начнем с вкладки Page и пройдем по опциям последовательно слева направо.
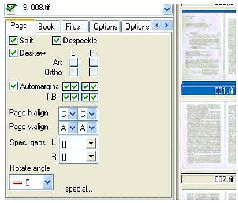
Уже упомянутый флажок Split отвечает за разбиение на страницы. Флажки Deskew (выровнять) и Despeckle (очистить от мусора) установлены по умолчанию для всех страниц. Флажки Art (свободный наклон) и Ortho (принудительный поворот) задают специальное выравнивание страницы. В подавляющем большинстве случаев можно обойтись без них. Группа параметров Page align (выравнивание текста) сообщают программе о типе верстки страницы. Буква А в списках означает автоматическое детектирование верстки. Практически для любой книги (если только это не зоологический справочник с обилием таблиц, вклеек и разной версткой по разделам) выравнивание текста по горизонтали следует выставить по центру («С»), а вертикальное – автомат («А»).

Вертикальное выравнивание стоит устанавливать только для страниц, имеющих явно нестандартную верстку (например, когда в текст книги включаются формы документов, выровненные посередине высоты страницы).
Вкладка Book.
На этой вкладке задаются единицы измерения (Units), величины добавляемых полей (Gaps) и размеры выходного изображения. Особое внимание стоит уделить полям Gap value(ширина поля).
При обработке ScanKromsator добавит белое поле именно такой ширины в изображение страницы.
Величину добавляемых полей можно установить в интервале 180-250 в зависимости от изначальной ширины полей книги.
Флажок vert.gap = hor.gap уравнивает ширину горизонтальных и вертикальных полей.
Остальные параметры можно не трогать, кроме флажка Merge pages after split (объединить после разбиения). Этот флажок пригодится, например, когда книга готовится к печати полными разворотами на листах альбомного формата (так иногда собирают дубликаты в библиотеках). Если этот флажок установлен, на выходе вы получите страницы с полями, склеенные по переплету.

Вкладка Files
На этой вкладке в поле Output folder (папка назначения) задается имя папки для выходных файлов, а в поле Ouput Prefix (префикс имени выходного файла) можно ввести «добавку» к имени файла, которая позволит отличить «сырые» сканы от обработанных. Параметры Start from / Step (Начальный номер/шаг) задают именование выходных файлов.
Особого внимания заслуживает группа параметров Ouput Format (выходной формат). В первом по счету списке выставляется формат упаковки TIFF-файла (уже упомянутый TIFF Uncompress). Следующий список задает разрешение вывода (DPI). Здесь нужно ОБЯЗАТЕЛЬНО выставить 600 dpi! Это включит оверсемплинг и облегчит в дальнейшем задачу распознавания, сжатия и печати.
Зачем нужен оверсемплинг?При распознавании текста программа «оконтуривает» символы по их контрасту с окружающим полем страницы. Затем полученные контуры сравниваются с эталонными, содержащимися в языковой базе данных. Если процент сходства достаточно велик, контур признается распознанным как тот или иной символ шрифта.В общих чертах, именно так работают алгоритмы OCR. Успех их работы сильно зависит от того, насколько велик абсолютный (в пикселах) размер символа в графическом файле. А этот самый размер напрямую зависит от разрешения файла. При разрешении 600 dpi на реальную ширину и высоту «бумажного» символа придется ровно вдвое больше пикселов графического изображения, чем при разрешении 300 dpi. Соответственно, вероятность успешного распознавания тоже вырастет, причем весьма существенно. Задача оверсемплинга – поднять разрешение скана до выходного, пересчитав определенным образом точки графического изображения.Оверсемплинг позволяет впоследствии спасти изображение от дефектов сжатия (за счет оольшого числа точек они становятся незаметны), а также помогает вывести изображение на печать наилучшим образом. Например, при печати файла DjVu 300 dpi на полном формате (масштаб 100 %) шрифт получается «рваным» из-за того, что преобразование серого скана в чисто черно-белое изображение дает много дефектов по краям букв, а принтер, имея собственное разрешение немногим больше 300 dpi, не в состоянии их исправить. Совсем иное дело – при печати документа с разрешением 600 dpi. В этом случае входное изображение принтера, имеюшее огромное количество точек, «ужимается» в размер реальной бумажной страницы.Особенности алгоритмов изменения размера приводят к тому, что границы символов разглаживаются, а резкость увеличивается.Разница между сжатыми страницами с разным разрешением заметна даже при просмотре на экране: на 300 dpi все дефекты, не устраненные обработкой, становятся заметны, а иногда изображения (например, полученные с бледного скана) вообше приходят в негодность.
Список Color (цвет) задает цветность выходного изображения. Для черно-белого текста и одноцветных рисунков выставляется пункт BAV. для черно-белых фотографических иллюстраций – Gray, для полноцветных изображений – Color (24bit). Впрочем, установка цветности для страницы в целом чаще всего бывает не нужна, поскольку есть возможность обрабатывать рисунки отдельно.
Больше всего проблем возникает, когда часть текста верстается поверх изображения (типичный прием для верстки детских книг). Такие страницы желательно вообще не подвергать обработке Кромсатором, а сразу подвергать распознаванию и запаковывать в PDF.

Вкладка Options.

На этой вкладке стоит только поднять до предпоследнего деления уже упоминавшиеся ползунки Text vert. sensitivity. В некоторых особо тяжелых случаях (вроде все тех же таблиц, отпечатанных на полупрозрачной бумаге), избавиться от «съедения» программой части символов можно, установив в списке Despeckle (очистка от мусора) пункт Safe.
Вкладка Options 2.

На этой вкладке заслуживает внимания один-единственный элемент – флажок LZW for nou-bw TIFFs (применить сжатие для не ч/б TIFF-файлов). По умолчанию этот флажок включен, но его стоит выключить, чтобы потом не страдать от проблем с открытием файлов в программах распознавания.
Вкладка Convert.
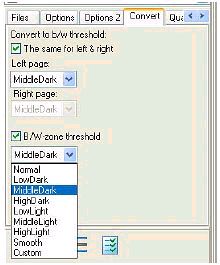
На этой вкладке задаются параметры преобразования изображения из градаций серого в чистое черно-белое. Группа параметров Convert to b/w threshold (Порог преобразования в ч/б) содержит три списка с идентичным набором пунктов. Два верхних из них отвечают за порог преобразования для четных и нечетных страниц, последний – за преобразование специально выделенных одноцветных рисунков.
Для оптимального результата при нормально читаемом с бумаги тексте лучше всего выставить во всех списках вкладки пункт MiddleDark. Если же результат будет негодным, с этими параметрами придется экспериментировать, так как единого рецепта дать здесь невозможно.
Вкладка Quality.
На этой вкладке выставляются параметры, напрямую влияющие на качество выходного изображения.
Флажок Enhance Image (применить улучшение) включает такую специальную обработку.
Первое, что нужно сделать на этой вкладке – держа Ctrl, установить галочку Gray Enhance (улучшить в градациях серого). Затем щелкаем по самой надписи, и попадаем в окно настройки дополнительных параметров Gray image enhance.

Здесь включаем (опять держа Ctrl) флажок Correct Illumination (Коррекция освещенности). Параметры – как на рисунке. Именно этот прием обеспечит нам избавление практически от всего мусора на сканах и получение чистых черно-белых страниц.

Маленькие хитрости

В окне Gray image enhance кроме вкладки Illumination всегда стоит заглянуть на вкладку Unsharp (контурная резкость). Если включить фильтр Unsharp Mask (знакомый практически каждому, работавшему с Adobe Photoshop), то он может неплохо выгладить края символов и улучшить их четкость. Параметры фильтра можно выставить как на рисунке.
Когда все дополнительные параметры выставлены, окно Gray image enhance можно закрыть, и перейти снова на вкладку Quality. Здесь включаем флажки Smooth (сгладить), Blur(размыть) и Sharpen (усилить резкость). Параметры везде можно выставить по 1. Однако если нужно улучшить читаемость книги (особенно с монитора), параметры Smooth и Blurстоит увеличить, например поставить Smooth = 2, Blur = 1, или в любом другом сочетании. Размытие краев символов позволяет придать им большую цельность при сжатии, и такой текст с монитора будет отлично читаем.
Последняя вкладка – PDF – отвечает за подготовку PDF-документа прямо в программе ScanKromsator, но я предпочитаю ее не трогать, и вам не советую.
2.4 Подготовка рисунков
После того, как все опции установлены и общие параметры пакетной обработки заданы, приходит время разобраться с рисунками (если таковые имеются в книге). Первое, что стоит сделать с найденным рисунком выделить его мышью.
Выделенная область в программе ScanKromsator носит название зоны (Zone). Чтобы выделенный рисунок распознавался программой как не подлежащий обработке, после выделения достаточно щелкнуть в инструментальной панели на кнопке Mark as Picture Zone -

(отметить как картинку). Впрочем, для одноцветных рисунков выделение необязательно, наоборот – преобразование в ч/б может сильно улучшить их восприятие.

Большие хитрости
Самая большая хитрость в подготовке черно-белых изображений – выбрать правильный способ их кодирования. Дело в том, что ScanKromsator может преобразовать изображение не только в черно-белое фотографическое (оно будет просто вырезано из страницы), но и в так называемое точечно-диффузное одноцветное (Bitonal Dithered Image). Суть этого процесса в том, что оттенки черно-белого изображения получаются путем изменения частоты расстановки отдельных черных пикселей. Фактически (с точки зрения алгоритма сжатия) такое изображение – одноцветное, то есть безградационное. Это позволяет очень существенно (до 20 раз!) выиграть в размере при сжатии алгоритмами, аналогичными LZW, DjVu, ZIP и другими. В случае JPEG сжатие может вообще не удаться, так как этот алгоритм рассчитан на плавные переходы оттенков.
Использовать Dithered Image возможно только на изображениях с высоким разрешением. Дело в том, что при отображении на экране или бумаге диффузного изображения с высоким разрешением происходит уменьшение, и отдельные черные и белые точки пересчитываются в серые. Если изображение не уменьшается при отображении, расположение точек становится заметным глазу, и изображение приходит в негодность.
Применять диффузное кодирование при работе в ScanKromsator имеет смысл при работе с фотографическими изображениями, напечатанными офсетом (на них виден небольшой растр) и глубокой печатью (на них мал общий контраст). Высококонтрастное или фактически одноцветное изображение кодировать диффузным способом опасно – можно «обсыпать» края контрастных объектов отдельными точками. Фактически, можно применить диффузное кодирование к любому изображению с достаточно высокой плотностью серого цвета и достаточно малым общим контрастом (например, таким, как показанное на рисунке выше).
Диффузное кодирование задается для выделенного рисунка кнопкой Exclude and Mark as Dithered Zone

(Исключить и отметить как зону диффузного кодирования) инструментальной панели, или командой меню Zones =› Exclude and Mark as Dithered Zone. При включении диффузного кодирования рисунок не изымается из страницы при обработке.
2.5 Обработка и подготовка выходных файлов
После того, как все настройки заданы и рисунки оформлены в виде зон – нужно проверить качество выходных файлов. Для этого следует выбрать несколько страниц, которые вам покажутся самыми «проблемными». Как правило, это страницы с рисунками, чертежами и таблицами. Каждая страница передается на обработку командой Process =› Current Fileили клавишами Ctrl+P.
ScanKromsator произведет обработку страниц по заданному настройками сценарию, а потом выведет специальный маленький просмотрщик с окном, подобным старым версиям ACDSec.

Перед запуском обработки программа может выдать запрос на изменение разрешения (DPI) изображения. На этот запрос нужно всегда отвечать утвердительно, иначе оверсемплинг применен не будет, и выходные файлы придут в негодность.
Когда экспериментальные файлы удовлетворили требованиям к качеству, приходит время запускать основной процесс обработки. Сами первичные выходные файлы лучше удалить, чтобы программа не застопорилась на них с запросом о перезаписи. Обработка запускается нажатием кнопки Process! инструментальной панели.
Длительность обработки целиком зависит от быстродействия компьютера, и в среднем составляет для 400-страничной книги от 20 минут до полутора часов.
После обработки в выходной папке будут находиться:
• Собственно выходные файлы со страницами книги, преобразованными в черно-белые одноцветные изображения;
• Рисунки, сохраненные под именами типа pic000l. tif.
В самих страницах на месте выделенных рапсе рисунков останутся «дыры».
Поэтому для получения изображений, пригодных для распознавания, нужно объединить страницы с рисунками. Это делается командой меню Zones =› Picture Zone =› Merge Zones. После окончания процесса объединения все выходные файлы будут готовы для распознавания.
Шаг 3. Распознавание и первичная вычитка
Вот, наконец, и пришло время для включения в процесс FineReader.
Да, великого и ужасного. Для цели книгосканирования лучше всего подойдет версия 9.0 Pro, но мне впору пришлась лицензионка 7.0 Pro, списанная за ненадобностью на работе. Шучу.
Первое, что нужно сделать – зайти в диалог опций пакета, и сбросить там все флажки на вкладке Сканирование/Открытие в группе Обработка изображений.
После этого нужно переместить куда-нибудь в известное место сам пакет, чтобы потом легко найти его. Я предпочитаю сохранять в папку, куда выводил изображения страниц ScanKromsator. Когда страницы открыты, можно сразу запускать распознавание.
Первичная вычитка в FineReader сводится к легкой коррекции самых заметных ошибок.
Главное правило при работе если вы собираетесь сохранять файл в DjVu, ни в коем случае не удаляйте знаки переноса строки и концевые дефисы абзацев! Тогда внедрить текстовый слой в DjVu-файл можно будет легко и быстро, и не возникнет проблем при модификации готовой книги.

Шаг 4. Сохранение и финальное редактирование
4.1 PDF или DjVu?
Вопрос выбора формата обязательно встает ребром, как только принимается решение преобразовать книгу в электронный вид. При выборе формата нужно учитывать несколько факторов. Чтобы лучше разобраться в них, приведу краткое сравнение особенностей форматов PDF и DjVu.
PDF изначально «компьютерный» издательский формат, рассчитанный на максимально точное отображение электронного документа на любых устройствах. Соответственно, он показывает наилучшие результаты именно при сохранении изначально электронных документов. PDF использует формат сжатия JPEG для графики и LZW для текста. Соответственно, лучше всего этому формату удается сохранение мультимедийных документов с полноцветным оформлением и обилием графики. Однако при сохранении сканированных страниц получается своего рода «суррогат»: текст, наложенный на сжатое JPEG изображение полного формата страницы. Такая методика дает большой проигрыш в размере (средняя книга из 300 страниц весит несколько сотен мегабайт), но приемлемое качество. PDF не переносит диффузных (Dithered) изображений, опять-таки из-за наличия в составе алгоритма JPEG. Сжатие превращает такие иллюстрации в подобие картин Казимира Малевича. Может, кому-то это понравится, но, ради спортивного интереса – посмотрите когда-нибудь на свой портрет, сжатый подобным образом…DjVu – динамично развивающийся формат, разработанный специально для хранения сканированных документов большого объема. По сути это многостраничный графический формат, являющий собой своеобразную надстройку над алгоритмом сжатия графики JBIG. Главная особенность DjVu – использование так называемых словарей, то есть наборов описаний контрастных контуров, специфичных для страницы. Таким образом, при достаточном единообразии изображения (например, типографского шрифта) – сжатие может проводиться в сотни раз!Использование словарей позволяет делить изображение на «слои», содержащие текст, графику и задний план. Специальных средств отображения текста формат DjVu не имеет, но позволяет хранить невидимый текстовый слой со сведениями о координатах расположения строк на изображении страницы. Такая структура дает возможность проводить текстовый поиск в файлах.Средняя книга в формате DjVu занимает не более 10 мегабайт.
Все сказанное заставляет подумать, что DjVu – идеальный формат для электронных книг. В целом это недалеко от истины. При обработке сканов обычных черно-белых книг, таблиц и справочников с относительно небольшим количеством иллюстраций и вклеек DjVu настолько сильно выигрывает в размере и качестве файла у PDF, что применять последний становится бессмысленно.
Совсем иная картина при сохранении широкоформатных журналов, детских богато иллюстрированных книг и разнообразных фотокаталогов и альбомов.
Здесь обилие полноцветной графики высокого разрешения нивелирует все достоинства JBIG (поскольку в факторе сжатия сложных изображений он существенно проигрывает JPEG). Кроме того, попытки кодера DjVu понизить цветность отдельных участков изображения при его сохранении – крайне отрицательно сказываются на качестве.
Собственно в моей практике было всего два случая, когда DjVu проиграл PDF. Оба раза это были книги с большим количеством иллюстраций – «Петрович и Патапум» и фотокаталог деталей для завода. На них DjVu все-таки дал более чем двухкратный выигрыш в размере по сравнению с PDF, но при этом проиграл в качестве на два порядка, и был забракован.
Собственно, общие рекомендации по выбору формата сохранения могу дать следующие:
• Для сохранения подавляющего большинства художественной и научной литературы, таблиц и справочников, альбомов чертежей и атласов – ничего лучше, чем формат DjVu на сей момент не существует;
• Для сохранения полноформатных иллюстрированных детских книг, комиксов, альбомов по искусству, цветных фотокаталогов – стоит применить формат PDF, тем паче, что такие издания обычно на мобильных устройствах не просматриваются.
4.2 Сохранение в формат PDF
Сохранение в формат PDF я лично предпочитаю выполнять в FineReader, с небольшой финишной обработкой в Adobe Acrobat. Если текст распознан без большого количества грубых ошибок – PDF-кодер Ридера выдает вполне приемлемые результаты. Но с настройками сохранения, выставленными в программе по умолчанию – вы будете сильно разочарованы качеством графики. Поэтому, прежде чем выдать программе команду на сохранение файла – я обязательно захожу в диалог настройки пакета FineReader, жму на вкладкеСохранение кнопку Форматы – и выставляю опции на вкладке PDF:

При показанных настройках рост размера сохраняемого файла составляет примерно 10-25 % но сравнению с настройками по умолчанию. Качество же графики растет на порядок, поэтому скупиться себе дороже. Выставив настройки, можно смело сохранять все распознанные страницы в один файл.
Единственная беда полученного файла – отсутствие оглавления. В принципе, для детской книжки или комикса это можно пережить, но вот в случае фотокаталога или альбома по искусству создать оглавление придется, чтобы потом не возиться с текстовым поиском. Для этого лучше всего обзавестись Adobe Acrobat какой-нибудь старой версии, вроде 7.0 – все задачи по созданию оглавления он решит отлично.
Создать оглавление в Adobe Acrobat очень просто. Найдя начало нового раздела, нужно скопировать текст его заголовка из рабочего поля, а потом щелкнуть на кнопке с «солнышком» на панели закладок, как она выглядит на рисунке. Появится свежая закладка на текущую страницу. Название новой закладки вводится таким же образом, как имя файла в «Проводнике» Windows. После того, как все закладки созданы, их можно с помощью простого перетаскивания распределить по уровням вложенности (разделы и подразделы).
Сохранив файл в последний раз, вы получите готовую электронную книгу.

4.3 Сохранение в формат DjVu
Для сохранения в формат DjVu понадобится программное обеспечение, работающее с этим форматом. Конкретно это:
• Специализированный DjVu-кодер LizardTech Document Express Enterprise 5.1;
• Процессор текстовых слоев DjVu OCR 2.4 (выложен на сервере по адресу http://www.djvu-soft.narodTu/soft);
• DjVu-редактор LizardTech Document Express Editor 6.0.1.
Вся операция сохранения начинается с настройки предварительно установленного кодера DjVu. Диалог настройки в LizardTech Document Express Enterprise вынесен в отдельное приложение, называемое Configuration Manager (Менеджер настроек). Запускаем это приложение.
Интерес здесь представляют профили кодирования, сгруппированные в списке Select Profile. Задача настройки (это нужно будет сделать всего один раз) состоит в том, чтобы подготовить три специальных профиля для кодирования изображения:

1. Одноцветный (Bitonal) на разрешение 600 dpi – для кодирования основной части книги и диффузных (Dithered) иллюстраций;
2. Фотографический (Photo) профиль на 300 dpi – для кодирования обложек и полноцветных иллюстраций;
3. Сканерный (Scanned) профиль на разрешение 600 dpi – для кодирования страниц с черно-белыми клишированными фотоиллюстрациями.
Для создания каждого профиля нужно сперва выбрать из списка Select Profile базовый профиль. Соответственно, для указанного списка это будут профили Bitonal (600dpi), Photo (300dpi) и Scanned (600dpi). Выбрав профиль, нажимаем кнопку Advanced Settings, не трогая никаких основных настроек. В появившемся диалоге на вкладках Text и Background выставляем параметры так, как показано на рисунках:
Для профиля Bitonal:

Для профиля Photo:

Для профиля Scanned:

Что сие означаетНа вкладках тонкой настройки профилей основное место занимают опции кодера – коэффициент усиления, обработка полутонов и яркостной составляющей и т. п. Трогать эти настройки нужно только в том случае, если требуется специальным образом закодировать сложное и объемное изображение. В случае книжных сканов в этом нет никакой необходимости, так что интерес будут представлять только группа параметров Text Quality, список JB2 Format, цифровое поле Pages per Dictionary и поляBack/Foreground Quality.Группа Text Quality задает методику кодирования контрастных контуров, опознанных по единообразию размеров (т. е. представляющих символы шрифта). Значения в этом списке можно менять только для профилей Scanned и Photo (в профиле Bitonal изменение установки качества на любую, кроме Most-loss (~aggressive) приводит к конфликту при работе кодировщика). На размер файла эти настройки влияют довольно слабо (для серых сканов и изображений размер меняется в пределах 20 % при установках от Lossless до Most-Loss).Поля Background Quality и Foreground Quality выставляют фактор сжатия JBIG соответственно для слоев заднего и переднего планов. На размер выходного файла влияют слабо, если только скан не снят с формата A3. В принципе, значения, показанные на рисунках, дают оптимальное качество в подавляющем большинстве случаев книгосканирования.Поле Pages per Dictionary – именно та настройка, наличие которой позволяет существенно сократить размер файла. Она задает максимальное количество страниц, на которые будет распространяться отдельный словарь. Это позволяет (за счет единообразия типографского шрифта) увеличить степень сжатия в несколько раз. В то же время, задавать большое количество страниц на словарь для профилей Photo и Scanned нецелесообразно – что приведет к ухудшению качества.
После того, как все настройки заданы, можно сохранить профили (дав им информативные имена, вроде Advanced Bitonal…), и приступить непосредственно к кодированию.
Для начала нужно рассортировать выходные файлы на несколько групп, каждую из которых будет кодировать свой профиль. В отдельные группы выделяем: файлы с текстом и диффузными черно-белыми иллюстрациями, текстом и черно-белыми недиффузными иллюстрациями, цветные и черно-белые вклейки.
Собственно, профиль Scanned нужен только для самых сложных случаев (страницы с текстом и высококонтрастными черно-белыми клишированными фотографиями, не поддающимися диффузному кодированию), основную работу сделают профили Bitonal и Photo. Группы файлов можно разобрать по папкам с именами профилей, чтобы потом не ошибаться с выбором. Затем запускаем приложение Workflow Manager пакета Document Express Enterprise.
Командой меню File =› Open Image… открываем первые из подлежащих кодированию файлов (но не обложку!). Как правило, первые страницы книги целиком черно-белые. Для них подойдет профиль на основе Bitonal. Смотря по характеру страниц, можно выбрать и другой профиль. Открыв изображение, выбираем для кодирования ранее подготовленный профиль из списка Raster Profile.

Если книга не имеет иллюстраций в тексте, все страницы, кроме обложек, можно сразу сохранить в один DjVu-файл. Если же имеются иллюстрации, цветные вклейки и т. п., то каждую страницу нужно сохранить в свой DjVu-файл, чтобы потом собрать их воедино в редакторе. Обычно, кодируя книгу, я заранее сохраняю первые страницы без иллюстраций в один DjVu-файл с именем, совпадающим с именем книги (соответственно, эти файлы уже не выделяю ни в какую группу для кодирования). Потом в папку, где лежит этот файл, кодирую все оставшиеся страницы – каждую в отдельный файл. Открыв затем редактором файл с именем «Название книги. djvu», просто добавляю к нему уже имеющиеся закодированные DjVu-файлы, предварительно отсортировав их по именам. Так легко и быстро можно получить готовый файл для добавления обложек.
Итак, открыв изображения, подлежащие кодированию тем или иным профилем, задаем в поле Job Name имя задания. Если книга сохраняется в один файл, то эта строка будет его именем. В противном случае все файлы DjVu, соответствующие страницам, будут сохранены с именами, совпадающими с именами файлов страниц.
Теперь время перейти с вкладки Workflow на вкладку Output. Здесь из списка Separate Files выбираем тип сохранения: One document only (единичный документ), либо Each file(каждый файл отдельно). Затем, щелкнув по ссылке Choose Folder… выбираем папку для сохранения выходных файлов DjVu. Если сохранение идет по одному файлу, крайне нежелательно сохранять DjVu-страницы в папку с выходными файлами ScanKromsator (папку с изображениями страниц) это очень затруднит выбор файлов для открытия редактором.

Каждая команда Open Images… (кроме первой после запуска программы) в Workflow Manager создает новое задание (Job). Параметры на вкладках можно выставлять отдельно для каждого задания. После того, как все готово, можно запустить задания на выполнение. Для этого достаточно поставить галочку рядом с именем каждого задания. К сожалению, индикация прогресса работы в Workflow Manager не предусмотрена. Однако кодер работает очень быстро, кодирование даже 500-страничного тома редко длится более 10 минут. Когда кодирование основной части книги завершено, можно открыть в Workflow Manager файлы с обложками и закодировать их в отдельные файлы DjVu, использовав ранее подготовленный профиль Photo.
Когда готов весь набор файлов DjVu (книга в одном файле или в виде страниц, обложки), можно сложить все файлы в одну папку, и приступить к сборке полноценной электронной книги. Запускаем Document Express Editor.

Открываем в Document Express Editor файл с первой страницей обложки.
Затем командами меню Edit =› Insert Page(s)… добавляем в нужные места все остальные подготовленные файлы. Теперь книга имеет законченный вид, и ее можно сохранить командой File =› Save As…
Остались сущие пустяки – добавить в книгу текст, распознанный в FineReader, и создать оглавление. Начнем с добавления текста. Находим в редакторе страницу, с которой начиналось распознавание и запоминаем ее номер (теперь он не первый, как это было в пакете FineReader, так как добавились обложка и форзац). Теперь закроем редактор, и запускаем приложение DjVuOCR 2.4 (автор – камрад Gencho из солнечной Болгарии).

Интерфейс этого процессора обработки DjVu интуитивно понятен. Нас интересует режим «Ручной OCR manager». Здесь нужно указать адрес папки пакета FineReader с распознанной книгой, номер первой страницы пакета в файле DjVu, а также имя самого файла DjVu. Флажок «Создать» не должен пугать – на самом деле, в существующий файл DjVu просто будет записан невидимый слой с текстами и координатами строк. Когда все параметры заданы, запускаем обработку. Проходит она очень быстро, и теперь файл DjVu готов к созданию оглавления.
На сайге http://www.djvu-soft.narod.ru можно найти несколько программ, предназначенных для автоматизации создания оглавления в файлах DjVu, но я, лично, предпочитаю полный контроль над этим процессом.

Если в книге нет непронумерованных вклеек, задача очень проста. Берем в руки книгу, и смотрим, как посчитать номер страницы в файле относительно номера страницы в книге. Теперь жмем кнопку Rectangular Hyperlink на инструментальной панели редактора. Нажав кнопку – выделяем область (например строку), которая станет ссылкой оглавления. Появляется диалоговое окно Rectangular Highlight/Hyperlink Properties:

К сожалению, процесс ручного создания оглавления не отличается удобством. Каждый раз придется выбирать тип ссылки Page Number в списке Link То:, а потом выбирать из списка Page номер страницы. Когда оглавление готово, файл сохраняется, и DjVu-книга готова!

4.4 Финальная вычитка и подготовка версии для PDA
Итак, книга для просмотра на мониторе или еВоок подготовлена. Но, если только это не технический справочник, вам наверняка охота получить еще и маленький файл для загрузки на PDA или любимый сотовый телефончик. Получить его будет опять-таки довольно утомительно, но фактически совсем не сложно. Берем пакет с распознанной книгой, открываем его в FineReader и сохраняем в формате ТХТ. Потом – открываем полученный файл в MS Word и приступаем к финальной вычитке. Тут самой главной проблемой будут оставленнные программами дефисы на месте переносов. Их удаление будет весьма монотонной, но достаточно быстрой работой. Лучше всего открытый в Word файл перевести в режим отображения «Веб-документ». Теперь остается только, прокручивая текст, искать неверные переносы на правой стороне экрана, и исправлять их. Переносы в FineReader не изменяются в таких случаях:
• Если слово с переносом расположено в конце страницы (перенос идет на следующую страницу);
• Если слова с переносом нет в словаре FineReader (словарь длиной не отличается, так что подавляющее большинство имен и фамилий, вся историческая и научная терминология – в группе риска).
Когда текст вычитан, наступает время заголовков и рисунков. Каких-либо рекомендаций по выделению заголовков – давать нет смысла, ибо кому что нравится. С рисунками придется повозиться чуть дольше. Во-первых, те из рисунков, которые были обозначены как диффузные (Dithered) в ScanKromsator – придется обозначить еще раз, уже как простые рисунки (Picture Zone), и обработать страницы с ними отдельно. Тогда рисунки выделятся в отдельные файлы. Теперь, с помощью Word эти файлы можно будет добавить в вычитанную книгу. Место для рисунка можно выбирать произвольным образом, если только он не привязан к тексту – тогда придется отыскать нужное место. Когда рисунок добавлен, щелкаем по нему дважды, запуская диалог Формат рисунка. Сейчас задача – сжать рисунок, для того, чтобы изображение высокого разрешения не «забивало» экран и память на мобильном устройстве. После нажатия на кнопку Сжать… вызывается диалог сжатия изображения. Параметры в нем выставляются так, как показано на иллюстрации. После получения ответа из диалогов Word обрежет и сожмет рисунок алгоритмом JPEG с фактором качества 50 %. Для мобильных устройств этого вполне достаточно из-за маленьких (максимум 640 х 480 точек) экранов.


Сохранять полученный файл лучше всего в формат HTML. Как показала практика, с ним не возникает проблем у большинства «читательных» программ на мобильных телефонах и PDA. Отдельные энтузиасты могут попробовать преобразовать полученный текст в набирающий популярность XML-совместимый формат FB2, но описание этого процесса требует отдельного руководства, так как для редактирования FB2 еще не создано устоявшегося набора удобных в использовании визуальных программ-редакторов. Можно попробовать преобразовать файл HTML в формат FB2 с помощью консольной утилиты AnyToFB2.ехе, но работа с ней выходит за рамки данного руководства. Для того чтобы выходной HTML-файл был совместим с основным WEB-стандартом HTML (не содержал служебной информации Word, отформатированной по спецификации Microsoft, не совместимой со стандартным HTML), сохранять нужно, задав в списке «Тип файла» пункт «Веб-страница с фильтром». При выборе этого пункта Word сперва спросит, в своем ли мы уме, что не сохраняем его служебные данные, но потом выведет в указанную папку две вещи: собственно HTML-файл ‹имя книги›.html с текстом книги, и подпапку с именем \‹имя книги›.files\ которая будет содержать сжатые рисунки и XML-таблицу совместимости Word.
Эти две вещи лучше всего сразу запаковать в ZIP-архив (большинство программ-читателей, вроде AlReader – сможет распаковать такие книги), чтобы ничего не потерять при переносе на мобильное устройство и не плодить в памяти отдельные папки под каждую книгу.
По завершении всех операций – вы получаете электронную книгу, практически неотличимую на вид (правда, на экране) от бумажной! Плюс версия для чтения на мобильнике.
Еще раз повторю: описать все эти операции гораздо труднее, чем выполнить их одну за другой.
Удачи в книгосканировании!
P.S. Примеры к этому руководству я получил, отсканировав и обработав книгу Лины Хааг «Горсть пыли». Если Вы хотите посмотреть, к чему приводит точное и неукоснительное исполнение правил, изложенных в руководстве – скачайте книгу по адресу http://torrents.ru/forum/viewtopic.php?t=2170096. Кроме того, эта книга сама по себе может быть весьма полезной, особенно любителям истории Второй мировой войны.
Контакты автора
Если Вы хотите найти автора в Сети, чтобы задать вопрос, предложить дополнение, кинуть ссылку на программу или просто сообщить любую полезную информацию, ищите его по таким адресам:
• http://torrents.ru/forum/profile.php?mode=viewprofile.ru=2964463 – основное представительство аффтара на трекере torrents.ru, здесь можно найти всю файловую базу для этого руководства, включая самые новые версии PDF- и DjVu-кодеров. Здесь же лежит в форумной ветке http://torrents.m/fomm/viewtopic.php?t=2160930 онлайн-версия руководства, доступная для обсуждения зарегистрированными пользователями. На форуме есть возможность отправки личных сообщений.
• Для особых случаев связи предназначен адрес электронной почты: #mailto: twdragon@mail.ru. Писать на него можно только, если Вы не зарегистрированы на torrents.ru, а вопрос не терпит отлагательств (например, срочно требуются выложенные на файлообменник старые программы для обработки DjVu, которых нет на трекерах). Все вопросы, касающиеся содержания руководства, рекомендую обсуждать в указанной выше форумной ветке. Однако, если Вы все же твердо решили задать свой вопрос по e-mail, обязательно сделайте в теме письма пометку «Руководство по книгосканированию», иначе ваше письмо сильно рискует улететь в корзину со спамом.
• http://www.journals.ru/iournals.php?userid=35132 – блог аффтара на одном из популярных российских дневниковых ресурсов. Найти здесь что-то полезное – нереально, ибо блог создавался специально для отвода потока сознания. Если Вы зарегистрированы на Journals.ru – милости прошу. Если же нет – будьте готовы к тому, что флудерские и просто глупые комментарии будут безбожно вытираться и перечеркиваться, так что основное правило таково: если Вы – «Гость» – пишите только по делу.
• Программы на файлообменники я выкладываю по запросу, обычно в течение одного дня (за исключением летней отпускной поры, тогда могу и в течение недели не управиться). Сервисы iFolder.ru, RapidShare.com, ShareMania.ru. FineReader не просите выложить никогда(!), ибо университетская лицензия не велит. Запросы на Adobe Acrobat тоже крайне нежелательны – у меня и самого этот монстр глючит безбожно.
То же от 4u4undr
Эта мини инструкция в картинках, описывающая полный цикл создания электронной версии научно-технической книги, и предназначена для человека, искренне захотевшего сделать приемлемого качества е-книгу, но не знающего с чего начать. Важно понимать, что существует немало апробированных методов создания достаточно качественных e-книг, все они характеризуются тем, что на выходе книга, как правило научно-техническая, имеет разрешения 600 dpi ч/ б (все книги в 300 dpi ч/ б, несмотря на все старания создателей, явно проигрывают).
Рассматриваемая здесь метода, основана на сканировании в300 dpi, в градациях серого (600 dpi ч/б будет после обработки). По этому поводу следует заметить, что уменьшение геометрического размера сырого скана в 4 раза, по сравнению со сканированием в 600 dpi, практически компенсируется увеличением глубины цвета в 8 раз (зато скорость сканирования возрастает в 2 раза ©), а также уменьшением количества паразитного мусора.
1. Сканирование
Беря в руки увесистую книгу, многие думают, что отсканировать ее может только маньяк. Совершенно верно, именно так. Без применения научно-организованного подхода, любая работа превращается в мучение, но, сделав работу незаметной, хоть большого удовольствия и не получишь, но дело сделаешь.
Для сканирования сгодится любая программа, способная взаимодействовать с TWAIN драйвером сканера и сохранять отсканированные изображения на диск, нумеруя их удобным способом. Сойдет любой просмотровщик графических файлов: ACDsee, IrfanView, XnView… Если ваш сканер поддерживается программой сканирования VueScan, можете использовать и ее.
Например, в IrfanView (скачайте свежую версию этой бесплатной программы) это выглядит примерно так:
В меню Файл жмем пункт Выбрать TWAIN-источник…

Далее, там же, выбираем пункт меню Получить изображение/пакетное сканирование…

здесь выбираем как будут нумероваться файлы сканов, где они будут складироваться и тип графического формата. Не забудем проверить Опции графического формата:

можно выбрать или Без сжатия или LZW (внимание, не все программы корректно с ним работают), в последнем случае размер файла на выходе будет примерно в два раза меньше. Можно, наверное, и ZIP, но это проверьте самостоятельно. – жмем на кнопку OK и переходим в окно TWAIN Вашего сканера
Сама техника сканирования незатейлива:
– берется книга, кладется разворотом (т.е. двумя страницами) на стекло, прижимается если надо сверху рукой (это быстрее, чем использовать груз).
– делается предварительное сканирование
– картинка, если это возможно, в окне сканирования, разворачивается на 90 градусов (в нормальное положение)
– выбирается область сканирования с некоторым запасом, как правило по горизонтали (по вертикали трудно промахнутся)
– мышкой жмется кнопка основного сканирования
– после того, как данный разворот отсканирован, во время обратного движения каретки сканера, переворачиваем страницу книги, кладем на то же место и жмем опять на левую кнопку мыши (курсор ведь остался на кнопке сканирования), и так пока книга не кончится.
Т.е. идея проста, сканируем развороты в слепую. Этим достигаем максимальной скорости сканирования, которая ограниченна только техническими характеристиками сканера, и полной свободы головы. Таким образом, во время сканирования, Вы можете заниматься многими другими вещами, да хоть кино посмотреть.
Небольших перекосов, отсканированных страниц, бояться не стоит, это будет исправлено при последующей обработке, но все же надо соблюдать аккуратность.
Не забываем, что сканируем с разрешением 300 дпи и в градациях серого (gray scale), если будете сканировать в черно-белом режиме при 300 дпи, то просто потеряете время (хорошая книжка уже не получится).
На выходе этого этапа получаем так называемый сырой материал – файлы в формате tiff с разрешением 300 dpi в градациях серого, обычно размер каждого файла, без использования сжатия, составляет примерно 8 мегабайт (4 при LZW).
Скорость сканирования может достигать до 200 и даже более развортов (400 страниц) в час, на сканере со скоростью 16 секунд на сканирование А4, т.е. сканирование среднестатистической книги, займет не более 2 часов времени!
Обычно первый и последний разворот книги содержат по одной странице. Ну, так и сканируем их по одной, т.е. все-таки придется сделать 3 предварительных сканирования на книгу ©.
2. Обработка
За обработку сырого материала отвечает замечательная, притом совершенно бесплатная, программа ScanKromsator от bolega (тут убедительная просьба, не надо сразу же бросаться и писать ему письма о том, как улучшить, углубить, да и просто спасибо, наверное, то же не надо посылать, просто сделайте хорошо несколько книг и поделитесь ими).
ScanKromsator это мощный инструмент, предназначенный для обработки сканированного материала, с целью создания качественных e-книг, со многими полезными и не очевидными для новичка функциями. Поэтому, просто следуйте пошаговой инструкции и все получится.
a) Запускаем программу и загружаем в нее файлы (список файлов слева сверху, под этим списком панель инструментов);

b) Выбираем путь для вывода результатов (закладка Files), тут же можно назначить способ нумерации выходных файлов, и что очень важно, назначить выходное разрешение 600 dpi;

c) Приступаем к черновому «кромсанию»;
Находим левее кнопки с надписью Process, кнопочку с ножницами(Draft kromsate), нажимаем, появляется окно диалога

ставим галочки на Split pages и safe top/bottom и жмем кнопку OK.
(если первая и/или последняя страницы одинарные, т.е. не разворот, то можно предварительно покромсать их отдельно (поле Kromsate = Current), соответственно не надо для них ставить галочку Split pages)
d) Минут через 10-15:

Обратите внимание на синенькие полосочки, это резаки (по которым Вы безошибочно отличите это программу от других ©), за их пределами все будет безжалостно отрезано, а данная страница будет разделена на две (см. центральные резаки). Посмотрите на то, что рядом с названиями страниц появились зеленые галочки!
e) Это короткий, но очень важный этап – расстановка опций.

Для этого пройдемся по закладочкам (слева в окне программы). Pages. На ней выставляем способ центрирования. По умолчанию стоит A – автомат, это значит поместить изображение в верхний левый угол. Но, как правило (это у меня так) горизонтальное выравнивание ставится по центру(Page h.align) C, вертикальное в низ(Page v.align) B или вверхT это зависит от форматирования книги.
Despeckle – убирание мелкого мусора.
Deskew – выравнивание наклона страницы, если в результате страница получится криво выровненной, то ее можно переделать с помощью метода Art (включение этого метода для всех страниц замедляет процесс) или Ortho если текст на данной странице развернут на 90 градусов.
Чтобы опция была применена ко всем страницам, при выборе ее удерживаем Ctrl.
Аналогично действуйте при выборе остальных опций, которые применяются ко всем страницам сразу.
На закладке Book выставляем размеры выходных страниц, оставляем Page width и height в Auto.

В поле H.Gap value ставим 200 (или 250) pixels, это значение обычно для обработки в 600 дпи, но если Вам хочется других размеров полей, то можете подобрать это значение по своему вкусу.
В закладке Files, как было сказано выше, ставим выходное дпи 600 (иначе ничего хорошего не получится). Это архи важно, от этого зависит весь окончательный результат.
Во вкладке Options, ставим Deskew method = Auot(shear), для Despeckle метод Safe или Fine+Normal это интеллектуальный метод очистки. Например, он не вычищает точки над i и j.

Options 2 пропускаем. В принципе, перед Draft kromsate на этой вкладке можно отрегулировать чувствительность, чтобы резаки не обрезали номера страниц при предварительном кромсании.
Вкладка Convert – выставляем порог для преобразования из градаций серого в черно-белый.

Для Convert to b/w threshold выбираем MiddleDark. Не забываем удерживать Ctrl при выборе опции, предназначенной для всех страниц. Но никто не мешает провести эксперимент для своего скана и выбрать другой параметр.
Ну, наконец, последняя, но очень важная вкладка Quality. В Enhance image ставим галочки для Blur и Sharpen, значения для них обычно 1 или 2 (набор этих опций и их значения не догма, можете поэкспериментировать, но для начала поставьте как на рисунке), для 2 результат будет пожирнее, выбирайте исходя из шрифта, сканируемой книги.

И опять очень важно, если у вас исходники это разворот книги, то жмем на Gray enhance и появляется диалог Gray image enhance, в нем ставим cleaner passes в 1, ставим галку на Correct low contrast и главное, что бы это заработало, ставим галку на Enable. По этой
опции происходит выравнивание освещенности (особенно важно это для центра разворота), что убирает черные полосы и кучу мусора. Незаменимая штука.

Здесь приведен вид диалогового окна для Gray image enhance для версии программы 5.6A, в предыдущих версиях нет Enable.
Галку для Correct low contrast можно не ставить, она важна в случае, когда тень на сгибе налезает на текст, при взведенной галке, буквы будут несколько ужирняться и расплываться.
Можно попробовать Smooth, по утверждению автора программы, применение этого метода приводит к некоторому уменьшению размера книги, за счет сглаживания контура букв. А в целом я советую, сделать 3-4 разворота, так, как описано, посмотреть результат, только потом экспериментировать по улучшению, но повторяю, в 95% случаев должно получится неплохо.
Кстати, часть выбранных опций можно сохранить на будущее в File-›Task options settings.
f) Самый скучный, но к счастью не очень долгий этап. Надо пройтись по всем страницам, с целью проверки правильности расстановки резаков.

Да, если не стоит большая зеленая галка, то поставьте ее (для запоминания вносимых изменений).
Если Вы увидите, что для какой либо страницы резаки установлены не правильно, то их надо поправить. Передвигаем резаки, если надо меняем способ центрирования для данной страницы (если текст на странице развернут на 90°, то для данной странице ставим Deskew = Ortho на закладке Pages).
Оптимально это делается так: левая рука отвечает за листание – кнопки q и w, правая за мышь, которой мы передвигаем, если надо резаки. Если Вы уверены, что для части страниц положение резака будет одинаково, то Вы можете скопировать их положение, нажав правую кнопку мыши на резаке, выберите нужную опцию (Copy current position to).

Бывает, что страница расположена под углом, или тень на развороте расширяется, для таких случаев можно устанавливать косые резаки, просто, удерживая шифт, передвигаем резак за его кончик, это быстрее, чем в последствии в ручную чистить страницы.
g) Кстати, знаете ли Вы, чтобы все не делать заново, задание можно сохранить (пункт основного меню File-›Save Task);
e) Жмем большую кнопку Process. Тут появляется предупреждения, в здравом ли мы уме, что меняем разрешение, но нам уже все равно, мы все уже сделали. Все, теперь дело за компьютером.
На компьютере Pentium M 1400 MHz, этот процесс занимает порядка одной минуты на разворот (это для версии 5.6A, в предыдущих версиях в 1.5-2 раза медленнее).
Часа через 2-3, в указанной ранее папке, нас ждет результат, просматриваем его внимательно, иногда могут быть несколько неправильно выровненных страниц. Их переделываем отдельно.
Перед переделкой страницы, на вкладке Book, необходимо переключить Page width на Fixed, этим мы зададим тот же размер страницы, который был подсчитан кромсатором для Вашей книги.
Совершенно не обязательно кромсать всю книгу сразу, можно делать это по частям. Просто, в последующих порциях, необходимо выставить Book -›Page width-›Fixed размер предыдущей части. Для определения правильного размера в кромсаторе, обычно, достаточно взять 10^15 разворотов (страниц).
Особо дотошные, могут почистить остатки вручную, так называемая тонкая очистка. Лично я это не делаю, за исключением убирания библиотечных штампов и записей на полях. Как правило, и так все замечательно. Кстати, в сканкромсаторе есть мощные средства для очистки сканов, можете воспользоваться.
(Если у Вас 256 и менее мегабайт памяти, то возможен глюк, он характеризуется постоянным свопом диска при смене dpi, тогда просто снимите задачу, выгрузите лишнее из памяти, запустите процесс кромсания заново)
О картинках. Если в книге встречаются фотографии, то самым простым, но не оптимальным по качеству способом является использование опять таки кромсатора ©. Во время просмотра результатов предварительного кромсания, выделите мышкой иллюстрацию и в контекстном меню (по правой кнопке мыши) выберите метод Exlude and Mark as dither regione.
3. Кодирование
Кодировать в djvu можно двумя способами.
Первый, использовать или свободно распространяемую программу Solo 3.1 (в этой программе используется старый алгоритм кодирования) или Document Express Editor версий от 4 до 6. Это делается просто, запускаем программу, загружаем первую страницу (только одну!), добавляем к первой странице остальные, но не более 500 (обычно 200^300). Сохраняем с выбором профиля bitonal и с разрешением 600 dpi.
Второй, рекомендованный способ, это использовать Document Express Enterprise 5.1 (доступна облегченная версия этого пакета, объемом около 20 мегабайт). Вначале создаем профиль для кодирования (делается это не часто, можно один раз), для этого запускаем Document Express Enterprise Configuration Manager из этого же пакета, из списка выбираем профиль Bitonal(600), нажимаем на кнопку Advanced Settings…, в диалоговом окне Advanced Settings выбираем закладку Text и ставим Pages Per Dictionary равным 1000 (конечно, это небольшой экстремизм, можно ограничиться значением 100^200). Сохраняем этот профиль под новым именем. Увеличение размера страниц на словарь, приводит к заметному уменьшению размера файла, до 25%.

Запускаем Document Express Enterprise Workflow Manager, загружаем все страницы зараз, в поле Job Name пишем название книги, из списка Raster Profile выбираем, подготовленный ранее профиль, переключаемся на закладку Output и из списка Separate Document(s) by выбираем One document only. Ставим галочку (с самого левого края подEnable) и ждем конца кодирования, следим или пока эта галка исчезнет или по закладке Log.
4. Создание текстового слоя
После того, как все уже сделано, остановится на этом просто себя не уважать, не говоря уж об остальных.
Для добавления распознанного текстового слоя в djvu книгу потребуется две программы. Первая это FineReader 7.0 или 8.0 версии. Вторая программа, это небольшая утилитаDjvuOCR 2.1 от болгарского камрада Gencho.
Загружаем все, обработанные в кромсаторе, тифы в FineReader, те из которых была сделана djvu книжка, и распознаем в пакетном режиме. После распознавания, ничего не правим, не вычитываем, просто сохраняем пакет на диск, желательно путь для того пакета надо выбирать попроще, у DjvuOCR могут быть проблемы, если в названии пакета и/или пути будут кириллические символы. С FineReader все. Ура, ура, ура, появилась новая версия этой утилиты 2.2, в которой сняты эти ограничения. Теперь можно редактировать текст после распознавания в ФР, соблюдая некоторые ограничения:
а) при редактировании сохранять некоторые символы оригинального текста (например интервалы), т.е. не переписывать большие блоки;
б) желательно сохранять количество строк в параграфе (т.е. не стирать знаки конца строки).
Кстати, для наших целей вполне подойдет триальная версия FineReader, которую можно свободно скачать с официального сайта разработчика.
Запускаем DjvuOCR, жмем на кнопку Manual made OCR manager

Далее, тоже все просто:
FineReader Project directory – выбираем каталог с проектом.
Output OCR text file – это любой, пустой текстовой файл, помещенный в каталог с проектом.
Ставим галочку на Burn DJVU file и выбираем djvu книжку.
Нажимаем Process.
Ждем несколько минут. И всё.

Добавление обложки
В добавлении обложки, если не преследовать сверхзадач, никаких особых хитростей нет. Сканируем обложку в цвете в 200 дпи, чистим ее по вкусу, слегка размываем ее и кодируем в djvu профилем Photo(300). Полученный файл добавляем в книгу, например с помощью Document Express Editor.
З.Ы. Поступают жалобы, что таким образом сделанная обложка имеет размер меньший, чем страницы книги, что выглядит не эстетично, поэтому делайте обложку, как Вам больше нравится, сохраняя размер в пределах разумного. Говорят, есть метода от Minor а по созданию сверх компактных обложек в 600 дпи, если не лень, поищите.
Оглавление
Знаете ли Вы, что в Вашу книгу можно вставить оглавление? А между прочим, благодаря уважаемому Shea, это поразительно просто! Для этого воспользуемся утилитой DjVu Hyperlinks Editor.
Добавляем книгу, указываем, на каких страницах находится оглавление (нумерация с учетом обложки), выставляем смещение 1 (для компенсации обложки) и жмем Создать!
Конечно, без глюков пока не обходится, проверьте на всякий случай результат, вопиющие случаи можно и поправить в ручную (см. вставку оглавления ручным случаем чуть ниже).
Аналогично, с помощью этой программы, можно создать предметный указатель (Тип работы).
Подробнее, обо всех возможностях программы, можно почитать в сопроводительном файле.

В 5 и 6 версии Document Express Editor это же можно сделать мышкой. Жмем на кнопку – прямоугольная гиперссылка, обводим пункт меню, выскакивает окно диалога – свойство гиперссылки, в котором выбираем линк на номер страницы и затем соответственно сам этот номер. Ну и так далее, пока рука не отсохнет. Только делаем это в самый последний момент, после добавления обложки, вкладок и пр., иначе ссылки сдвинутся.

7. Использованные программы и где их взять
IrfanView www.irfanview.com freeware
ScanKromsator http://www.djvu-soft.narod.ru/ freeware
Solo 3.1 http://www.djvu-soft.narod.ru/ freeware
Document Express Editor http://www.djvu-soft.narod.ru/?
Document Express Enterprise http://www.djvu-soft.narod.ru/?
ABBYY FineReader www.abbyy.com. trial
DjvuOCR 2.1 http://djvuocr.ucoz.ru/ freeware
DjVu Hyperlinks Editor http://www.djvu-soft.narod.ru/ freeware
Заключение
Несколько о ФайнРидере.
Если Вы собираетесь сделать научно-техническую книгу в формате djvu – не надо использовать ФР для сканирования и обработки сканов!
Примите это как данность, если Вы хотите получить качественный результат, несмотря на предлагаемые ФР удобства по типа всё-в-одном, попробуйте все же данную инструкцию.
Из основных недостатков:
– использование сжатия на основе jpeg, что, как минимум, приведет к раздуванию е-книги после кодирования;
– примитивно реализованный алгоритм выравнивания страницы;
– если Вы сканируете в 300 дпи в градациях серого, то вся обработка будет выполнена
– для этого разрешения, в то время как в кромсаторе, сначала идет ресемплинг до 600.
Помните, что все вышеизложенное, не есть истина в последней инстанции, просто здесь систематизирован подход, практически гарантирующий неплохой результат. Но никто не запрещает, как использовать другие методики (Фотошоп с плагинами, BookRestorer, Corel PHOTO-PAINT, RasterlD…), так и экспериментировать с кромсатором (но вначале, настаиваю, сделайте несколько разворотов строго по инструкции, что бы было с чем сравнивать). Путей получения хорошего скана книги много, главное на выходе иметь 600 дпи!

